Artificial Intelligence/NLP
Text Representation
테리는당근을좋아해
2024. 8. 19. 20:28
1. Text Representation
- Text Representation은 NLP에서 텍스트 데이터를 컴퓨터가 이해 및 처리할 수 있는 형식으로 변환하는 기법을 말한다.
- 텍스트는 원래 비정형 데이터기 때문에, 정형 데이터로 변환해야 머신 러닝 모델이나 다른 알고리즘에 사용할 수 있다.
1) Text Representation의 중요성
- 텍스트를 어떻게 표현하냐에 따라서 모델의 성능이 크게 좌우 된다. 좋은 텍스트 표현 방식은 텍스트의 의미와 문맥을 잘 유지하면서 계산 효율이 높아야 한다.
2) 주요 Text Representation 기법
| 기법 | 개념 | 장점 | 단점 |
| One-Hot Encoding | 각 단어를 고유한 백터로 표현하는 방법으로 벡커의 크기는 단어 집합의 크기와 같다. 단어가 존재하는 위치에만 1, 나머지는 0으로 설정된다. 예: 단어 집합이 ["cat", "climbing", "development"]일 때, "cat"은 [1, 0, 0]으로 표현 |
단순하고 구현이 용이 | 단어 간 유사성을 표현하지 못하며, 단어 집합이 클수록 희소성(sparsity) 문제가 발생 |
| Bag of Words(Bow) | 텍스트 내 단어들의 출현 빈도를 기반으로 텍스트를 벡터로 표현. 문맥이나 단어의 순서를 고려하지 않는다. |
구현이 쉽고 기본적인 특징 추출로 널리 사용 | 문맥 정보의 손실, 희소성 문제, 차원의 저주 |
| TF-IDF(Term Frequency-Inverse Document Frequency) | 단어의 빈도 뿐만 아니라 단어의 중요도를 반영하는 가중치를 부여 자주 등장하지만 덜 중요한 단어(예: "the", "a")보다는 특정 문서에만 자주 등장하는 단어에 더 큰 가중치를 부여 |
흔한 단어의 중요도를 낮추고, 문서에 특이한 단어의 가중치를 높이는 방식으로 보다 정교한 텍스트 표현이 가능 | 단어 간의 관계나 문맥을 반영하지 못한다. |
| Word Embeddings | 단어를 실수 벡터로 변환하는 방법으로 단어 간의 유사도를 학습할 수 있다. 임베딩 벡터는 고정된 차원을 가지며, 같은 공간 내에서 유사한 의미를 가진 단어들은 유사한 벡터 값을 가진다. 대표적인 임베딩 기법으로 Word2Vec, GloVe, FastText등이 있다. |
단어 간의 관계와 문맥을 반영해 유사한 의미를 가지는 단어들을 가깝게 표현할 수 있다. | 대규모 Corpus를 학습해야 하며, 미리 학습된 임베딩을 사용할 경우 특정 도메인에 특화되지 않을 수 있다. |
| Contextualized Word Enbeddings | 문맥을 반영한 임베딩으로, 같은 단어라도 문맥에 따라 다른 벡터로 표현된다. BERT, GPT, ELMo와 같은 모델이 여기에 해당한다. |
문맥(특히, 문장 수준)을 반영해 더 풍부하고 의미 있는 표현을 제공한다. | 모델의 크기와 복잡도가 커지고, 계산 비용이 많이 든다. |
| Sentence/Document Embeddings | 문장이나 문서 단위의 텍스트를 임베딩 벡터로 표현하는 기법 Universal Sentence Encoder, Sentence-BERT 등이 해당한다. |
문장이나 문서 단위의 의미를 잘 보존할 수 있으며, 문장 간의 유사도 계산에 유용하다. | 문장의 길이나 복잡성에 따라 표현력이 달라질 수 있다. |
3) Text Representation 선택 기준
- 텍스트 표현 방식을 선택할 때는 다음과 같은 요소를 고려해야 한다.
a. 문제의 특성
- 분류, 감정 분석, 번역 등 NLP 작업에서 어떤 표현 방식이 적합한가
b. 테이터의 양과 질
- 작은 데이터셋에서는 간단한 표현 기법이 적합할 수 있고, 대규모 데이터셋에서는 복잡한 임베딩 방식이 더 효과적일 수 있다.
c. 계산 비용
- 고성능 모델은 더 많은 계산 자원과 시간이 필요할 수 있으므로, 주어진 리소스에 맞게 표현 방법을 선택해야 한다.
2. Bag of Words(BoW)
- 텍스트 데이터를 벡터로 표현하는 가장 기본적인 방법으로 문맥이나 순서를 고려하지 않고, 텍스트 내의 단어들의 출현 빈도만을 기반으로 텍스트를 표현한다.
- 각 Document는 단어의 집합으로 간주되며, 단어들의 빈도 정보가 중요한 특징이 된다.
1) 원리
a. 단어 집합(Corpus)의 구성
- 문서 집합(Corpus) 내의 모든 고유한 단어들을 추출해 단어 집합(Vocabulary)를 만든다.
- 예를 들어, 아래 두 문서의 단어 집합은 {I, love, machine, deep, and, learnig}이 된다.
- Document 1: I love machine learning and deep learning
- Document 2: I love machine learning
Corpus vs Vocabulary vs Document Collection
Corpus
Corpus는 NLP에서 수집된 텍스트 데이터의 집합을 의미한다.
일반적으로 Corpus는 여러 개의 문서로 구성되며, 특정 언어, 주제 또는 도메인을 나타낼 수 있다.
예를 들어, 뉴스 기사, 블로그 포스트, 책의 텍스트 등이 Corpus에 해당한다.
단어 집합(Vocabulary)
단어 집합은 Corpus에 포함된 모든 고유한 단어들의 목록이다. Corpus에 등장하는 모든 단어를 한 번씩만 포함하며, 중복된 단어는 제외된다.
예를 들어, 위 Document에서 단어 집합은 {I, love, machine, deep, and, learnig} 이다.
문서 집합(Document Collection)
문서 집합은 Corpus에서 추출한 개별 문서들의 모음이다. Corpus 자체가 여러 문서로 이루어진 집합으로, 문서 집합은 Courpus와 동일한 의미로 사용될 수 있다.
예를 들어, 위 Document의 집합이 문서 집합을 이룬다.
정리하면,
Corpus는 NLP에서 사용할 수 있는 텍스트 데이터의 전체 집합을 의미한다.
단어 집합(Vocabulary)은 Corpus 내에서 등장하는 모든 고유 단어들의 목록이다.
문서 집한(Document Collection)은 Corpus를 구성하는 개별 문서들의 모음이다.
따라서, 단어 집합과 문서 집합은 Corpus에서 파생된 개념으로, Corpus는 이를 포함하는 더 큰 개념이다.
b. 벡터화(Vertorization)
- 각 단어를 고정된 길이의 벡터로 변환한다. 벡터의 길이는 단어 집합의 크기와 동일하며, 각 위치는 해당 단어가 문서에 몇 번 등장했는지를 나타낸다.
- 예를 들어, 위의 두 문장은 아래와 같이 벡터화가 된다.
- Document 1: {1, 1, 1, 1, 1, 2}
- Document 2: {1, 1, 1, 0, 0, 1}

2) Bag of Word의 장점
- 간단하고 직관적이기 때문에 초기 또는 간단한 NLP 작업에 적합하다.
- 단순히 단어의 출현 빈도만 계산하기 때문에 계산 속도가 빠르다.
3) 단점
- 단어 순서와 문맥을 전혀 반영하지 않기 때문에 문맥 정보가 손실된다.
- 단어 집합이 커질수록 희소 행렬이 생성되어 계산 및 메모리 비용이 증가하고, 차원의 저주에 빠질 수 있다.

3. TF-IDF
- TF-IDF(Term Frequency-Inverse Document Frequency)는 단어 빈도(Term Frequency, TF)와 역문서 빈도(Inverse Document Frequency, IDF)를 결합해 텍스트 내 단어의 중요성을 계산한다.
1) Term Frequency (TF, 단어 빈도)
- 특정 단어가 한 문서 내에서 등장하지를 나타내는 지표
- 단어가 문서 내에서 자주 등장할수록 해당 단어는 그 문서에서 중요한 단어로 간주한다.
- $ TF(t,d) = \frac{n(t,d)}{\sum_{k}n(k,d)}$
- $n(t,d)$는 문서$d$에서 단어 $t$의 등장 횟수
- $k$는 문서 $d$에 있는 모든 단어를 나타내는 인덱스
- $n(k,d)$는 단어 $k$가 문서 $d$에 등장한 빈도
- $\sum_{k}n(k,d)$는 문서 $d$의 총 단어 수
- 예를 들어 "machine"이라는 단어가 문서 $d$에서 3번 등장했고, 문서 $d$의 총 단어수가 100이라면 $TF=\frac{3}{100}=0.03$이다
2) Inverse Document Frequency (IDF, 역문서 빈도)
- 단어가 전체 문서 집합에서 얼마나 드물게 등장하는지를 나타내는 지표
- 자주 등장하는 단어는 대부분의 문서에서 공통적으로 존재할 가능성이 높기 때문에, 상대적으로 중요하지 않은 것으로 간주한다.
- 드물게 등장하는 단어는 특정 문서에 더 특화된 정보일 가능성이 높아 더 높은 가중치를 준다.
- $IDF(t, D)=log(\frac{N}{1+DF(t)})$
- $N$은 전체 문서의 수
- $DF(t)$는 단어 $t$가 등장하는 문서의 수
- 예를 들어, N이 1,000인 문서 집합에서 단어 "machine"이 10개의 문서에 등장한다면, $IDF$는 다음과 같다
- $IDF(machine, D)=log(\frac{1000}{1+10}) = log(\frac{1000}{11}) \approx 2.897$
- 분모에 1을 더하는 이유는 모든 특정 단어가 모든 문서에 등장하거나, 하나도 등장하지 않는 경우를 처리하기 위한 smoothing을 적용
- 로그를 취하는 이유는 드물게 등장하는 단어들의 가중치가 지나치게 커지는 것을 방지하고 IDF 값의 범위를 조절하여 모델의 안정성을 높이기 위함이다.
3) TF-IDF
- TF-IDF는 TF와 IDF를 결합해 단어의 중요도를 계산한다.
- 단어가 문서 내에서 자주 등장하면서도, 전체 문서 집합에서는 드물게 등자알 때 높은 가중치를 부여한다.
- $TF-IDF(t, d, D)=TF(t,d) \times IDF(t, D)$
- 예를 들어, 특정 문서 $d$에서 "machine"이라는 단어의 $TF$가 0.03이고, $IDF$가 2.897이라면, 해당 단어의 TF-IDF를 계산하면 아래와 같다
- $TF-IDF(machine, d, D) = 0.03 \times 2.897 \approx 0.087$
4) 장점
- 문서 내에서 자주 등장하는 단어와 전체 문서에서 자주 드물게 등장하는 단어에 가중치를 부여함으로써 중요하지 않은 단어("the", "a")에 높은 가중치를 주는것을 방지할 수 있다.
- 각 문서를 고차원 벡터로 표현해 문서간 유사도를 계산할 수 있다.
5) 단점
- 단어의 순서나 문맥을 고려하지 않기 때문에 문맥 정보는 손실된다.
- 문서 집합이 클수록 희소성 문제로 인해 계산 및 메모리 비용이 증가한다.
- 미리 정의된 단어 집합을 기반으로 하기 때문에, 새로운 문서가 추가되면 단어 집합과 TF-IDF 값을 다시 계산해야할 수 있다.
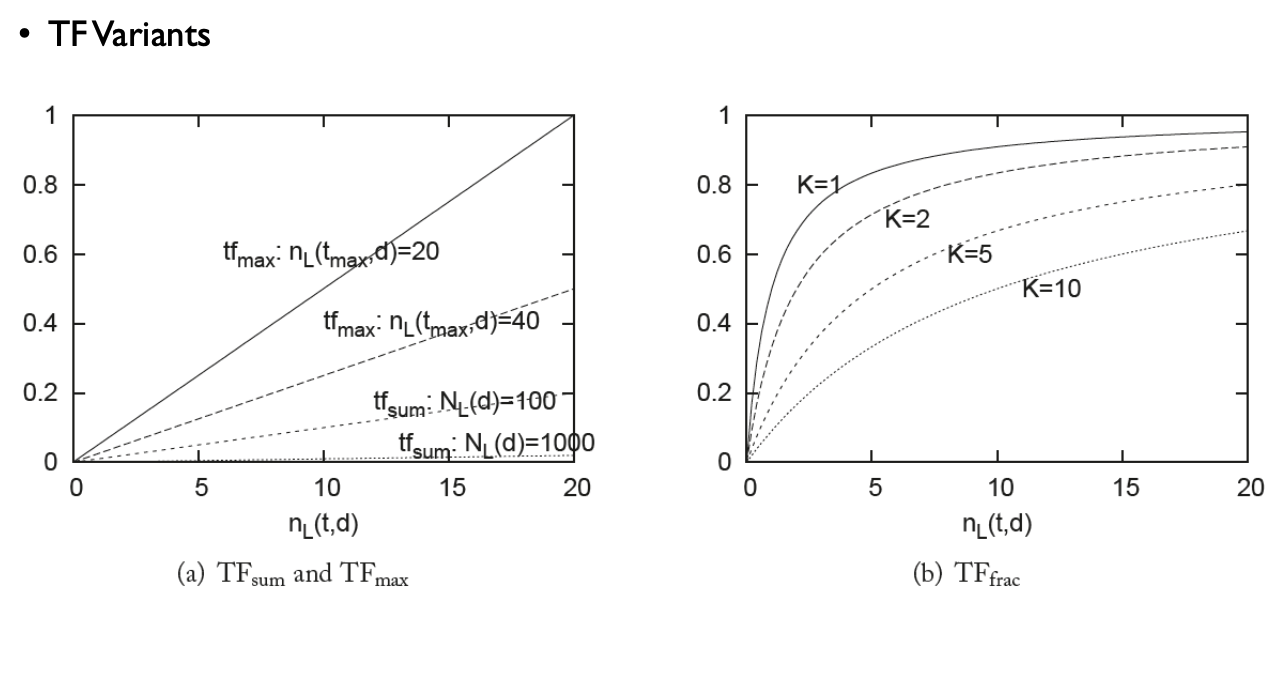
6) TF-IDF Variants

- $TF_{total}(t, d)$ : 특정 단어 $t$가 문서 $d$에서 나타나는 전체 빈도(단순 합계) 계산
- $TF_{sum}(t,d)$ : 단어 빈도를 문서의 전체 길이로 나눈 값으로, 문서의 길이에 따른 단어의 상대적 빈도를 나타낸다.
- $TF_{max}(t,d)$ : 특정 문서에서 가장 많이 등장한 단어에 대한 비율로 단어 빈도 계산, 다른 단어와 비교해 해당 단어가 상대적으로 얼마나 중요한지를 평가한다.
- $TF_{log}(t,d)$ : 로그 변환으로 자주 등장하는 단어의 빈도 차이를 완화해 중요도 계산에서 단어의 과도한 영향을 줄인다.
- $TF_{frac, K}(t,d)$ : 단어 빈도를 특정 사수 $K_d$로 나누어 상대적 빈도로 변환한다. 이는 특정 문서의 특성에 맞추어 가중치를 조절할 때 사용할 수 있다.
- $TF_{BM25, k_{1}, b}(t,d)$ : BM25 알고리즘에서 사용되는 TF 변형으로, TF 뿐만 아니라 문서 길이, 평균 문서 길이 등을 고려해 단어의 가중치를 계산한다. $k_1$과 $b$는 조정 가능한 파라미터로 문서 길이에 따른 가중치를 조절한다.

- $df_{total}(t,c)$ : 기본적인 문서 빈도 계산으로, 단어 $t$가 corpus $c$의 문서들에서 등장한 총 문서의 수
- $df_{sum}(t,c)$ : 문서 빈도를 전체 문서 수 $N_D(c)$로 나누어 정규화. 전체 문서에서 단어의 상대적 출현 비율을 나타낸다.
- $df_{sum, smooth}(t,c)$ : 문서 빈도에 스무딩을 적용, 0의 빈도를 가지는 단어 방지한다.
- $df_{BIR}(t,c)$ : BM25에서 사용되는 Variants로 특정 단어가 등장하지 않는 문서의 비율을 사용해 문서 빈도를 조정한다.
- $df_{BIR, smooth)$ : BM25 Variants에 스무딩을 적용해 변동성을 줄인다.

- Term frequency Variants
- n (natural) : 기본적인 TF, 즉 특정 단어가 문서에 등장한 횟수를 그대로 사용한다.
- l (logarithm) : TF에 로그 변환을 적용해 빈도 차이를 완화한다.
- a (aumented) : 단어의 빈도를 0.5와 해당 문서에서 가장 자주 등장한 단어의 빈도로 보정한다.
- b (boolean) : 단어가 문서에 등장하는지 여부에 따라 1 또는 0을 할당한다.
- L (log average) : TF에 로그 변환을 적용하되, 문서의 평균 TF와 비교해 보정한다.
- Document Frequency Variants
- n (no) : DF를 사용하지 않는다. 즉, 모든 단어에 대해 동일한 가중치를 사용한다.
- t (idf) : IDF를 사용해 흔한 단어의 가중치를 낮추고 드문 단어의 가중치를 높인다.
- p (probabilistic idf) : 문서의 개수에서 특정 단어가 등장하는 문서의 개수를 뺀 값으로 사용해 IDF를 보정한다.
- Normalization Variants
- n (none) : 정규화를 하지 않는다. 즉, 벡터 길이의 영향을 받지 않는다.
- c (cosine) : cosine 정규화를 통해 벡터의 크기를 1로 만든다.
- u (pivoted unique) : pivot 기반의 고유 정규화를 사용한다.
- b (byte size) : 문서의 바이트 크기를 기반으로 정규화한다.
4. N-gram
- N-gram은 연속된 N개의 단어 또는 문자의 시퀀스를 의미하며, 텍스트릐 문맥을 파악하거나 특정 패턴을 인식하기 위해 사용된다.
1) 기본 개념
Unigram (N=1)
- 단어 하나를 단위로 하는 N-gram으로 텍스트에서 각 단어가 독립적으로 취급된다.
- 예를 들어, "I love deep learning"이라는 문장은 ["I", "love", "deep", "learning"]이라는 네 개의 Unigram으로 표현된다.
Bigram (N=2)
- 연속된 두개의 단어로 구성된 N-gram으로 단어의 순서를 고려해 문맥적인 정보를 더 많이 포함한다.
- 예를 들어, "I love deep learning"이라는 문장은 ["I love", "love deep", "deep learning"]이라는 세 개의 Bigram으로 표현된다.
Trigram (N=3)
- 연속된 세 개의 단어로 구성된 N-gram으로 Bigram보다 더 많은 문맥 정보를 포함하지만, 차원이 더 커지게 된다.
- 예를 들어, "I love deep learning"이라는 문장은 ["I love deep", "love deep learning"]이라는 두 개의 Trigram으로 표현된다.
n-gram (N=n)
- 일반적으로 n-gram은 연속된 N개의 단어로 구성된 시퀀스를 의미한다.
- N 값이 커질수록 더 긴 문맥 정보를 포함하지만, 차원이 급격히 증가해 계산 비용이 증가하게 된다.
2) 특징
- 문맥 정보 보존
- 단어의 순서를 고려해 텍스트를 분석하기 때문에, 단어 간 연관성을 유지한다.(예: New York)
- 차원의 증가
- N이 커질수록 가능한 N-gram의 수가 기하급수적으로 증가하기 때문에, 차원의 저주로 인한 계산과 메모리적 비용이 증가한다.
- 회소성(Sparsity) 문제
- 모든 가능한 N-gram을 고려할 경우, 대부분의 N-gram이 특정 문서나 문장에 존재하지 않게 되고, 이는 희소 벡터를 생성해 계산 효율성을 떨어뜨린다.
3) 응용
- 언어 모델링(Language Modeling)
- N-gram은 언어 모델을 구축할 때 자주 사용된다.
- 예를 들어, 특정 단어가 주어진 문맥에서 발생할 확률을 계산하기 위해 N-gram을 활용해 문장을 생성하거나 다음 단어를 예측하는 작업을 수행할 수 있다.
- 텍스트 분류(Text Classification)
- N-gram을 사용해 텍스트 데이터를 벡터화 해 문서의 주제나 감정을 분류하는 작업에 사용할 수 있다.
- 예를 들어, 이메일 스팸 필터링에서 특정 단어 조합이 스팸 메일에서 자주 나타날 수 있다.
- 정보 검색(Information Retrieval)
- 검색 엔진에 N-gram을 활용해 사용자 쿼리와 문서 간 유사도를 계산할 수 있다.
- 자동 완성(Auto-completion)
- N-gram 모델은 입력된 단어 시퀀스에 따라 다음에 올 가능성이 높은 단어를 제안할 수 있다.
- 예를 들어, "I love"라는 입력이 주어지면, N-gram 모델에 따라 "you" 또는 "computer"와 같은 단어를 예측할 수 있다.
4) 한계와 제안
- 데이터 요구량
- N이 커질수록, 의미 있는 통계를 얻기 위해 필요한 데이터는 기하급수적으로 증가한다.
- 문맥 길이 제한
- N-gram 모델은 고정된 N개의 단어만 고려하기 때문에, 더 긴 문맥 정보나 문장 구조를 반영하지 못한다.
- 예를 들어, 문장의 처음과 끝에 있는 단어 간의 관계 파악은 어렵다는 한계가 있다.
- 대안 모델
- N-gram의 이러한 문제점을 극복하기 위해 신경망 기반 언어 모델이나 Word Embedding(예: Word2Vec, CloVe) 또는 Contextualized Embedding(예: BERT, GPT)등이 등장했다.