Lexical Analysis
어휘 분석은 텍스트 데이터를 전처리하는 단계로 문자 시퀀스를 의미 있는 단위인 토큰으로 변환하는 과정이다.
1. Sentence Splitting
- Sentence Splitting, Sentence Boundary detection, Sentence Segmentation
- 연속된 텍스트를 개별 문장으로 나누는 작업
1) Importance
- 분석 단위 : NLP 작업은 문장을 기본 단위로 분석하고 올바른 문장 분리는 텍스트를 정확하고 효과적으로 처리할 수 있도록 한다.
- 맥락 보존 : 텍스트를 문장으로 세분화함으로써 정보의 맥락적 일관성을 유지할 수 있으며, 이는 의미와 관계를 이해하는데 중요
- 오류 감소 : 적절한 문장 분리는 이후 처리 단계에서 오류를 줄여 POS-tagging, Syntax Analysis 과 같은 작업에서 더 정확할 결과를 가지고 올 수 있도록 한다.
2) Challenges
- Ambiguity : 마침표, 느낌표, 물음표 등의 구두점은 문장 경계를 나타내지만, 약어(예: "Dr.", "e.g."), 숫자(예: "3.14"), URL 등 다른 맥락에서도 사용될 수 있다.
- Language Specificity : 언어는 고유한 구두점 규칙과 문장 구조를 가지고 있다.
- Quotation Marks and Parentheses : 인용 부호, 괄호 내의 문장은 중첩, 구두점이 일관되지 않게 사용될 때
3) Techniques
- Rule-Based Methods
- Simple Heuristics: 기본적인 규칙을 적용하여 구두점과 공백을 기준으로 문장을 분할
- Regular Expressions: 정규 표현식을 사용하여 약어와 같은 복잡한 패턴을 처리
- Machine Learning Methods
- Supervised Learning: 주석이 달린 Corpus에서 패턴을 학습하여 문장 경계를 인식하는 모델을 훈련
- Sequence Labeling: CRF(Condition Random Filed) 또는 순환 신경망(RNN을 사용하여 텍스트의 각 문자 또는 토큰을 문장 경계로 레이블링
- Hybrid Methods
from nltk.tokenize import sent_tokenize
import re
text = "안녕하세요. 저는 삼성전자 반도체 연구소 소속입니다.. 오늘 날씨가 덥네요!"
print("NLTK")
sentences = sent_tokenize(text)
print(sentences) # ['안녕하세요.', '저는 삼성전자 반도체 연구소 소속입니다.. 오늘 날씨가 덥네요!']
print()
print("regural expression")
sentences = re.split('(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?|\!)\s', text)
print(sentences) # ['안녕하세요.', '저는 삼성전자 반도체 연구소 소속입니다..', '오늘 날씨가 덥네요!']2. Tokenization
- 텍스트를 의미있는 단위로 나누는 과정으로 NLP의 초기 단계
1) Challenges
- 복잡한 구문 - John's 는 하나의 토큰인가?
- 하이픈 처리 - "database" vs. "data-base" vs. "data base")
- 특수 문자와 기호 - "C++", "A/C", ":-)", "...", "ㅋㅋㅋㅋㅋㅋ"
- 공백이 없는 언어 - 중국어(今天天气很好)
from nltk.tokenize import word_tokenize
import jieba
import re
# 단순한 토큰화
text = "John’s sick and he is not going to school today."
tokens = word_tokenize(text)
print(tokens) # ['John', '’', 's', 'sick', 'and', 'he', 'is', 'not', 'going', 'to', 'school', 'today', '.']
# 특수 문자, 하이픈 처리 토큰화
def tokenize(text):
return re.findall(r"\b\w+(?:[-./+]\w+)*\b|\S+", text)
text = "data-base, A/C, ㅋㅋㅋㅋㅋㅋ"
print(tokenize(text)) # ['data-base', ',', 'A/C', ',', 'ㅋㅋㅋㅋㅋㅋ']
# 띄어쓰기가 없는 중국어 토큰화
text = "今天天气很好"
tokens = jieba.cut(text)
print(list(tokens)) # ['今天天气', '很', '好']
3. Morphological Analysis
- 단어를 의미있는 최소 단위인 형태소로 분해하거나 단어의 원형을 찾는 과정
- 이 과정에서 사용되는 주요 기법으로 Stemming(어간 추출)과 Lemmatization(표제어 추출)이 있다.
1) Stemming(어간 추출)
- 단어의 어근을 찾아서 변형된 단어를 해당 어간으로 축소시키는 과정
- 단어의 접미사나 어미를 제거하여 어근을 추출
- 단어의 형태만을 고려하며 문법적 또는 의미적인 처리는 고려하지 않는다.
- 어간 추출을 단어의 축소된 형태로 텍스트를 일반화하는데 유용하다.
2) Lemmatization(표제어 추출)
- 단어의 표준형, 사전에 등재된 형태로 변환하는 과정
- 단어의 형태와 문맥을 고려하여 처리
- 단어의 의미를 유지하면서 텍스트를 처리하는데 유용하다.

import nltk
from nltk.stem import PorterStemmer, WordNetLemmatizer
from nltk.tokenize import word_tokenize
nltk.download('punkt')
nltk.download('wordnet')
sentence = "He is running and eating at the same time."
tokens = word_tokenize(sentence)
stemmer = PorterStemmer()
stemmed_words = [stemmer.stem(word) for word in tokens]
print(stemmed_words) # ['he', 'is', 'run', 'and', 'eat', 'at', 'the', 'same', 'time', '.']
print()
lemmatizer = WordNetLemmatizer()
lemmatized_words = [lemmatizer.lemmatize(word) for word in tokens]
print(lemmatized_words) # ['He', 'is', 'running', 'and', 'eating', 'at', 'the', 'same', 'time', '.']
4. Part-of-Speech(POS) Tagging (품사 태깅)
- 주어진 문장 또는 문장의 단어에 해당하는 단어의 품사를 태깅하는 과정
- 각 단어가 문장 내에서 어떤 역할을 하는지 정확하게 분석하는데 사용
- 단어의 의미를 파악하고 문장의 구조를 이해하는데 필수적

1) POS-Tagging Algorithm
a. Pointwise prediction
- 각 단어를 개별적으로 Classifier를 사용하여 예측하는 방법
- Maximum Entropy Model, SVM
b. Probabilistic models
- Generative sequence models
- 문장 전체의 가장 가능성 있는 품사 시퀀스를 찾아내는 모델
- 문자이 주어졌을 때 문장의 품사 시퀀스의 조건부 확률을 계산해 가장 높은 확률을 갖는 시퀀스를 선택
- Hidden Markov Model(HMM)
- Discriminative sequece models
- 문장 전체의 품사 시퀀스를 한번에 예측하는 모델
- 문장의 특성과 문맥을 고려하여 특정 시퀀스를 예측
- Conditional Random Field(CRF)
c. Neural network-based models
- RNN, LSTM, Transformer 등의 인공 신경망을 사용
- 단어의 문맥을 잘 이해하고 다양한 특성을 학습할 수 있는 장점이 있다.
2) Maximum Entropy Model(MEM, Conditional Maximum Entropy)
- 주어진 단어에서 단어의 품사가 발생할 확률 분포를 결정하는데 사용
- 이 분포는 가능한 모든 분포 중에서 엔트로피가 최대가 되도록 선택한다.
엔트로피가 최대가 되도록 선택한다?
엔트로피는 확률 분포의 불확실성을 측정하는 지표로, 가능한 모든 분포 중에서 엔트로피가 최대가 되도록 선택된다는 말은 엔트로피가 확률 분포의 불확실성을 최대로 만드는 분포를 선택한다는 의미
엔트로피의 개념
엔트로피(Entropy): 정보 이론에서는 확률 분포의 불확실성을 나타내는 척도로 사용. 확률 변수가 다양한 값들을 가질 확률이 균등하게 분포될수록 엔트로피는 높아지며, 그 확률이 하나의 값으로 집중될수록 엔트로피는 낮아진다.
최대 엔트로피 분포: 가능한 모든 확률 분포 중에서 엔트로피가 최대가 되는 확률 분포를 의미. 이는 확률 분포가 가장 많은 정보를 제공하거나, 가장 많은 불확실성을 갖게 하는 분포이다. 예를 들어, 동전 던지기의 경우 앞면과 뒷면이 나올 확률이 0.5로 균등할 때 엔트로피가 최대가 된다.
최대가 되도록하는 이유?
정보 이론의 관점: 이 분포가 가장 많은 정보를 제공하거나, 가장 많은 불확실성을 포함하기 때이다. 이는 데이터의 예측 가능성이 낮고, 다양한 결과가 나올 가능성이 크다는 것을 의미한다. 따라서 엔트로피가 최대가 되도록 선택함으로써 가능한 모든 결과에 대해 공평하게 고려할 수 있는 기준을 제공한다.
확률 분포의 특성: 엔트로피가 최대가 되도록 선택될 때, 각각의 상황이 발생할 확률이 최대한 골고루 분포되므로, 그 상황들 사이의 정보적 거리가 가장 클 수 있다. 이는 예측 모델링이나 통계적 추론에서 다양성을 중시하는 관점에서 중요한 개념이다.
따라서 "엔트로피가 최대가 되도록 선택한다"는 말은 정보 이론에서 분포의 불확실성을 최대한 확대하는 선택을 한다는 의미로 해석할 수 있다.
a. 기본 원리
- Feature Functions
- 각 입력 단어에 대해 Feature function을 정의
- 예를 들어, 단어의 형태, 주변 단어, 문맥 등이 Feature function으로 사용될 수 있다
- Weights
- 각 Feature function에는 가중치가 할당된다.
- 가중치는 Feature function이 품사 태그에 미치는 영향력을 나타낸다.
- Learning and Reasoning
- 주어진 학습 데이터를 사용해 Feature function과 Weight를 학습한다.
- 학습 데이터에서 관찰된 Feature에 대해 가장 적합한 가중치를 찾는 것이 목표이다.
- 추론 단계에서는 새로운 단어가 주어졌을 때, 각 품사 태그에 대한 확률을 계산하고 가장 높은 확률을 가진 태그를 선택한다.
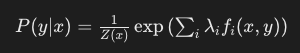
- MEM 확률 모델
- MEM은 주어진 입력 데이터 $x$(단어)에 대해 각 클래스 $y$(품사 태그)의 조건부 확률 $P(x|y)$를 예측
- $Z(x)$는 Normalization Constant로 입력 $x$에 대해 모든 가능한 태그 시퀀스에 대한 확률
- $\lambda_{i}$는 각 feature function에 대한 가중치
- $f_i(x, y)$는 Feature function
- 모든 가능한 품사 태그 시퀀스에 대해 함수 형태로 모델을 정의하고, 학습 데이터에서 관찰된 Feature function의 기대값을 최대화하는 방향으로 학습
b. Example: "She likes to eat apples."
- Tokenization: ["She", "likes", "to", "eat", "apples", "."]
- Feature 추출: 각 단어와 그 주변 문맥(주변 단어, 문장 위치 등)을 특징으로 사용한다. 예를 들면, "likes"라는 단어 주변에 나타나는 단어들이나 문맥을 특징으로 추출한다.
- 가중치 계산: 각 특징(주변 단어, 문장 위치 등)에 대해 MEM은 학습 데이터에서 관찰된 빈도나 중요도에 따라 가중치를 계산한다. 예를 들어, "likes"가 동사로 태깅되는 빈도가 높다면 해당 특징에 높은 가중치가 할당한다.
- 모델 학습: 학습 데이터에서 많이 나타난 특징이나 패턴을 학습하여 새로운 데이터에 대해 정확한 품사 태깅을 수행할 수 있도록 한다.
- 추론: 학습된 모델은 새로운 문장(예: "She likes to eat apples.")에 대해 각 단어의 품사 태그를 예측한다. 각 단어의 특징을 사용하여 확률을 계산하고 가장 높은 확률을 가진 품사를 선택한다.
3) Hidden Markov Model (HMM)
- 확률 기반의 생성 모델로, 문장 내에서 단어와 그 품사 간의 숨겨진 상태를 모델링해 동작한다.
a. 기본 개념
- Hidden State : 단어 시퀀스 내에서 각 단어에 대응하는 Hidden State(품사)가 존재. Hidden State는 관측 데이터(단어)에 의해 조건부로 결정
- Observation State : 실제 관측 데이터로 문장에서 각 단어들을 의미
b. 구성 요소
- States : 각 단어의 품사를 나타내는 상태로 Hidden State로 표현
- Transition Probabilities(상태 전이 확률) : 각 품사(State)에서 다른 품사(State)로 전이할 확률. (예를 들어, 동사 다음 명사가 나올 확률)
- Emission Probabilities (관측 확률) : 각 품사(State)에서 실제 단어(Observation State)가 관측될 확률로 특정 품사에서 특정 단어가 나타날 확률을 의미

c. 동작 방식
- 학습(Training) : 태깅된 문장을 사용해 상태 전이 확률과 관측 확률을 학습한다.
- 추론(Inference) : 학습된 HMM을 사용해 새로운 문장에 대해 POS-Tagging을 수행한다.
import nltk
from nltk.tag import hmm
train_data = [[('She', 'PRP'), ('likes', 'VBZ'), ('to', 'TO'), ('eat', 'VB'), ('apples', 'NNS')],
[('He', 'PRP'), ('likes', 'VBZ'), ('to', 'TO'), ('read', 'VB'), ('books', 'NNS')]]
trainer = hmm.HiddenMarkovModelTrainer()
tagger = trainer.train(train_data)
sentence = "She likes to eat apples."
tokens = nltk.word_tokenize(sentence)
pos_tags = tagger.tag(tokens)
print(pos_tags) # [('She', 'PRP'), ('likes', 'PRP'), ('to', 'PRP'), ('eat', 'PRP'), ('apples', 'PRP'), ('.', 'PRP')]
4) Conditional Random Fields(CRFs)
- Discriminative Model로 주어진 입력 시퀀스 $X$에 대해 조건부 확률 $P(X|Y)$를 직접 모델링
a. 기본 개념
- 판별적 모델
- Discriminative Model로 주어진 입력 시퀀스 $X$에 대해 조건부 확률 $P(X|Y)$를 직접 모델링한다. HMM과 같은 Generative Model과 달리, 입력 시퀀스와 출력 레이블 시퀀스 간의 조건부 확률을 추정하는 방식이다.
- 조건부 확률
- 입력 시퀀스 $X = (x_1, x_2, ..., x_n)$가 주어졌을 때, 출력 레이블 시퀀스 $Y=(y_1, y_2, ..., y_n)$의 조건부 확률 $P(Y|X)$를 최대화한다.
- 이 확률은 Feature function $f_k(y_{t_1}, y_t, x, t)$의 선형 조합을 통해 모델링된다.
- Feature Function
- 특징 함수 $f_k(y_{t_1}, y_t, x, t)$는 현재 상태 $y_t$, 이전 상태 $y_{t-1}$, 입력 시퀀스 $x$ 및 현재 시간 $t$에 대한 특성을 나타낸다.
- 주어진 입력에 대해 특정 상태 전이가 얼마나 가능한지를 나타내는 데 사용된다.
b. CRF의 수식적 표현
- CRF의 조건부 확률 $P(Y|X)$는 다음과 같이 정의된다.

- $Z(X)$는 Normalization Constant로, 모든 가능한 출력 시퀀스에 대해 확률의 합이 1이 되도록 한다.
- $\lambda_k$는 특징 함수 $f_k$에 대한 가중치
- $f_k(y_{t_1}, y_t, x, t)$는 주어진 입력 시퀀스와 상태 전이에 대한 특징 함수
c. CRFs 학습 과정
- CRFs는 입력 시퀀스와 대응하는 출력 레이블 시퀀스를 포함하는 학습데이터를 사용해 학습한다.
- 주로 MLE(Maximum Likelihood Estimation)를 통해 학습 과정이 수행되며, $\lambda$를 최적화하여 학습 데이터에 대한 로그 우도 함수를 최대화하는 것이다.
import sklearn_crfsuite
from sklearn_crfsuite import metrics
train_sents = [
[('She', 'PRP'), ('likes', 'VBZ'), ('to', 'TO'), ('eat', 'VB'), ('apples', 'NNS')],
[('He', 'PRP'), ('likes', 'VBZ'), ('to', 'TO'), ('read', 'VB'), ('books', 'NNS')]
]
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
def sent2labels(sent):
return [label for token, label in sent]
def word2features(sent, i):
word = sent[i][0]
features = {
'word': word,
'is_first': i == 0,
'is_last': i == len(sent) - 1,
'is_capitalized': word[0].upper() == word[0],
'is_all_caps': word.upper() == word,
'is_all_lower': word.lower() == word,
'prefix-1': word[0],
'prefix-2': word[:2],
'prefix-3': word[:3],
'suffix-1': word[-1],
'suffix-2': word[-2:],
'suffix-3': word[-3:],
'prev_word': '' if i == 0 else sent[i - 1][0],
'next_word': '' if i == len(sent) - 1 else sent[i + 1][0],
}
return features
X_train = [sent2features(s) for s in train_sents]
y_train = [sent2labels(s) for s in train_sents]
# CRF 모델 초기화 및 학습
crf = sklearn_crfsuite.CRF(
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=True
)
crf.fit(X_train, y_train)
test_sent = [('She', 'PRP'), ('likes', 'VBZ'), ('to', 'TO'), ('eat', 'VB'), ('apples', 'NNS')]
X_test = [sent2features(test_sent)]
y_test = [sent2labels(test_sent)]
y_pred = crf.predict(X_test)
# 결과 출력
print([word for word, _ in test_sent]) # ['She', 'likes', 'to', 'eat', 'apples']
print(y_test[0]) # 'PRP', 'VBZ', 'TO', 'VB', 'NNS']
print(y_pred[0]) # ['PRP' 'VBZ' 'TO' 'VB' 'NNS']
Generative Model vs Discriminative Model in POS-tagging
Generative Model
생성 모델은 각 단어의 나타날 확률과 단어가 주어진 POS 태그로 나타날 확률을 동시에 학습한다.
주어진 문장에서 단어 시퀀스와 POS 태그 시퀀스를 동시에 모델링하므로, 문장의 구조를 고려하여 태깅을 수행할 수 있다.
Discriminative Model
각 단어의 특성(주변 단어, 문맥 등)을 고려해 그 단어의 POS 태그를 예측한다.
문장 내에서 각 단어의 POS 태그가 다른 단어의 POS 태그에 의해 영향을 받을 수 있는 조건부 확률을 학습한다.
차이점
1. 학습 방식
- 생성 모델은 문장 전체의 확률 분포를 학습해 문장 구조를 고려한다.
- 판별 모델은 각 단어의 특성과 주변 문맥을 바탕으로 단어별 POS 태그를 분류한다.
2. 모델 구조
- 생성 모델은 문장 내 단어 시퀀스와 POS 태그 시퀀스 간의 관계를 모델링한다.
- 판별 모델은 조건부 확률을 사용하는 모델을 이용해 각 단어의 POS 태그를 독립적으로 예측한다.
5) Neural Network-based Models
a. Window-based Model vs Sentence-based Model
- Window-based Model
- 주어진 단어와 그 주변 단어들(Window)만들 사용해서 품사를 예측한다.
- 국소적인(contexual) 정보를 활용하는데 강점을 가지고 있다.
- 계산 효율성이 높고, 간단한 구조로 빠른 학습이 가능하다.
- 긴 문맥 정보를 반영하지 못하며, 문맥이 길어질수록 성능이 저하된다.
- Sentence-based Model
- 전체 문장의 정보를 사용해서 품사를 예측한다.
- 문장 전체의 문맥을 고려하므로 더 복잡한 의존성을 학습할 수 있다.
- 문장 전체를 처리하기 때문에 상대적으로 계산 비용이 높다.
b.RNN Model
- 이전 상태의 정보를 다음 상태로 전달해 문맥 정보를 유지해서 품사를 예측한다.

- Input Layer
- 문장이나 문서를 구성하는 단어들
- 각 단어는 Word Embedding등을 통해 변환된 벡터 형태로 표현된다.
- Recurrent Layer
- 각 시간 단계에서 이전 단계의 출력을 입력으로 받아 처리한다.
- 순환을 통해 문장 내의 단어들 사이의 순서와 의미적인 관계를 학습한다.
- LSTM(Long Short-Term Memory)와 같은 모델을 사용해 단순 RNN이 가지는 Long-term dependency의 어려움을 해결할 수 있다.
- Output Layer
- Recurrent Layer의 마지막 출력을 이용해 각 단어의 품사를 예측한다.
- 출력층에서 활성화 함수를 사용해 각 품사에 대한 확률 분포를 출력한다.
- Long-term dependency(장기 의존성) 문제 : 단순 RNN은 긴 시퀀스에서의 Long-term dependency를 학습하는데 어려움이 있어, LSTM(Long Short-Term Memory), GRU(Gated Reccurent Unit)과 같은 변형 모델이 사용된다.
import numpy as np
from keras.models import Sequential
from keras.layers import LSTM, Dense, Embedding, TimeDistributed, Bidirectional
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
# 샘플 데이터
sentences = [
"The cat sits",
"A dog barks",
"The bird flies"
]
labels = [
["DET", "NN", "VB"],
["DET", "NN", "VB"],
["DET", "NN", "VB"]
]
# 토크나이저 생성 및 학습
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
# 텍스트를 시퀀스로 변환
X = tokenizer.texts_to_sequences(sentences)
X = pad_sequences(X, padding='post')
# 레이블을 시퀀스로 변환
label_tokenizer = Tokenizer()
label_tokenizer.fit_on_texts(labels)
y = label_tokenizer.texts_to_sequences(labels)
y = pad_sequences(y, padding='post')
# 모델 구성
model = Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=8, input_length=X.shape[1]))
model.add(Bidirectional(LSTM(units=8, return_sequences=True)))
model.add(TimeDistributed(Dense(len(label_tokenizer.word_index) + 1, activation='softmax')))
# 모델 컴파일
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 모델 학습
model.fit(X, np.expand_dims(y, -1), epochs=10, verbose=1)
# 예측
predictions = model.predict(X)
predicted_labels = np.argmax(predictions, axis=-1)
# 예측 결과 출력
for i, sentence in enumerate(sentences):
print(f"Sentence: {sentence}")
print(f"Predicted POS tags: {[label_tokenizer.index_word[idx] for idx in predicted_labels[i] if idx != 0]}")
print()
# 실제 출력 결과
# Sentence: The cat sits
# Predicted POS tags: ['det', 'det', 'nn']
# Sentence: A dog barks
# Predicted POS tags: ['det', 'nn', 'vb']
# Sentence: The bird flies
# Predicted POS tags: ['det', 'nn', 'nn']
c. Hybrid Model : LSTM(RNN) + ConvNet + CRFs
- LSTM(Long Short-Term Memory)
- 이전 상태를 현재 상태에 전달하면서 데이터의 장기 의존성을 캡쳐
- 문장의 단어 시퀀스에서 각 단어의 특징을 추출
- ConvNet(Convolutional Neural Network)
- 합성곱 연산을 통해 지역적인 패턴을 추출하고, 입력 데이터의 특징 맵을 생성
- 각 단어의 주변 문맥을 합성곱 연산을 통해 처리하고 단어의 의미적 특징을 추출
- CRFs(Conditional Random Fileds)
- 시퀀스 데이터에서 각 단어의 레이블을 동시에 예측
- 각 단어의 주변 문맥을 모두 고려해 시퀀스의 레이블을 결정
- 동작 방식
- 입력 데이터 처리
- 입력 문장의 각 단어에 Word Embedding을 수행해 고차원 벡터로 표현
- 특징 추출
- LSTM과 ConvNet을 통해 각 단어의 특징을 추출
- LSTM은 단어의 시퀀스 정보를 고려한 장기 의존성을 학습
- ConvNet은 지역적인 문맥을 고려해 단어의 특징을 추출
- CRFs
- LSTM과 ConvNet으로 추출된 특징을 CRFs에 입력으로 주어 각 단어의 POS 태그를 예측
- 입력 데이터 처리
5. NER(Named Entity Recognition)
- 주어진 텍스트에서 특정 카테고리(예: 사람 이름, 조직 이름, 위치, 날짜 등)에 속하는 단어 또는 구를 인식하고 분류
- 검색 엔진, 문서 요약, 질의 응답 시스템에 활용

1) 목적과 중요성
- 정보 추출: 텍스트에서 중요한 정보를 자동으로 추출하고 유용한 데이터를 구조화된 형식으로 변환
- 문서 요약: 문서에서 주요 엔티티를 인식해 주요 내용을 요약
- 검색 및 질의 응답 시스템: 사용자의 질문에서 중요 엔티티를 인식해 더 정확한 답변을 제공
- 데이터 연결 및 통합: 다양한 출처에서 추출한 정보를 연결해 더 완벽한 데이터를 구축
2) 접근 방식
a. Dictionary/Rule-based Approach
- 미리 정의된 엔티티 목록이나 규칙을 사용해 엔티티를 인식
- List Lookup
- 미리 정의된 목록에 포함된 엔티티만 인식
- 간단하고 빠르며 언어 독립적. 유지보수가 쉽다.
- 이름이 바뀌거나 새로운 엔티티를 처리할 수 없으며, 모호성을 해결하는데 한계가 있다.
- Shallow Parsing
- 엔티티가 내부 구조를 가지고 있다는 점에 기반, 특정 패턴(예: 대문자로 시작하는 단어 + "Street")을 사용해 엔티티를 식별
- 패턴을 기반으로 빠르게 엔티티를 인식
- 복잡한 문장 구조나 표현이 바뀔 경우 처리하는데 한계가 있다.
b. Model-based Approach
- 머신 러닝을 통해 엔티티를 인식하고 분류
- CRFs(Conditional Random Fields)
- 단어 간의 관계를 고려해 엔티티를 인식
- 문맥을 고려한 정확한 엔티티 인식이 가능하다.
- 학습에 많은 비용이 소모된다.
- LSTM(Long Short-Term Memory)
- 긴 문맥을 고려해 엔티티를 인식
- 긴 의존성을 효과적으로 학습해 정확한 엔티티 인식이 가능하다.
- 복잡한 모델로 인해 학습 속도가 느려질 수 있다.
- CNN(Convolutional Neural Network)
- 단어 시퀀스의 지역적인 특징 패턴을 추출하고 학습해 엔티티를 인식
- 특징 패턴을 효과적으로 인식해 빠르게 엔티티를 추출할 수 있다.
- 긴 묵맥을 고려하는 데 한계가 있다.
import spacy
from transformers import pipeline
text = "Apple is looking at buying U.K. startup for $1 billion"
nlp = spacy.load("en_core_web_sm")
ner_pipeline = pipeline("ner", grouped_entities=True)
doc = nlp(text)
entities = ner_pipeline(text)
print("spaCy>>")
for ent in doc.ents:
print(ent.text, ent.label_)
print()
print("Hugging Face>>")
for entity in entities:
print(entity["word"], entity["entity_group"])
# spaCy>>
# Apple ORG
# U.K. GPE
# $1 billion MONEY
# Hugging Face>>
# Apple ORG
# U LOC
# K LOC'Artificial Intelligence > NLP' 카테고리의 다른 글
| Text Representation (0) | 2024.08.19 |
|---|---|
| 구문 분석(Syntax Analysis) (0) | 2024.07.30 |
| Hidden Markov Model for Part-Of-Speech Tagging (0) | 2024.07.17 |
| Maximum Entropy Model (MEM) for Part-Of-Speech Tagging (0) | 2024.07.16 |
| Text Processing - Introduction (0) | 2024.07.14 |



댓글